Deep Learning with Python(3), Neural Network with Keras
In 'Deep Learning with Python', the author introduces the differences between Keras and TensorFlow and presents three methods for building neural networks with Keras: the Sequential API, the Functional API, and Model subclassing. The Functional API is the most common method.

TensorFlow and Keras
TensorFlow is a Python-based, free, open source machine learning platform, developed primarily by Google. Keras is a deep learning API for Python, built on top of TensorFlow, that provides a convenient way to define and train any kind of deep learning model.
Keras is a powerful tool for building most types of neural networks, particularly for beginners or when simplicity and ease of use are prioritized, so we will focus on using Keras for neural networks.
Keras Functional API
The Functional API is a powerful method for building neural networks, especially for complex architectures. Here’s how you might stack two layers using the Functional API:
from tensorflow import keras
from tensorflow.keras import layers
inputs = keras.Input(shape=(3,), name="my_input")
features = layers.Dense(64, activation="relu")(inputs)
outputs = layers.Dense(10, activation="softmax")(features)
model = keras.Model(inputs=inputs, outputs=outputs)
model.summaryYou can use ChatGPT to learn more about the function of each step in building neural networks. Most deep learning models have multiple inputs or multiple outputs. It’s for this kind of model that the Functional API really shines. we will look at the following example:
from tensorflow import keras
from tensorflow.keras import layers
vocabulary_size = 10000
num_tags = 100
num_departments = 4
# Define model inputs.
title = keras.Input(shape=(vocabulary_size,), name="title")
text_body = keras.Input(shape=(vocabulary_size,), name="text_body")
tags = keras.Input(shape=(num_tags,), name="tags")
# Combine input features into a single tensor, features, by concatenating them.
features = layers.Concatenate()([title, text_body, tags])
# Apply an intermediate layer to recombine input features into richer representations.
features = layers.Dense(64, activation="relu")(features)
# Define model outputs
priority = layers.Dense(1, activation="sigmoid", name="priority")(features)
department = layers.Dense( num_departments, activation="softmax", name="department")(features)
# Create the model by specifying its inputs and outputs
model = keras.Model(inputs=[title, text_body, tags], outputs=[priority, department])You can train your model in much the same way as you would train a Sequential model, by calling fit() with lists of input and output data. These lists of data should be in the same order as the inputs you passed to the Model constructor.
import numpy as np
num_samples = 1280
# Dummy input data
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
# Dummy target data
priority_data = np.random.random(size=(num_samples, 1)) department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data], epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict( [title_data, text_body_data, tags_data])You can plot a Functional model as a graph with the plot_model() utility.
keras.utils.plot_model( model, "ticket_classifier_with_shape_info.png", show_shapes=True)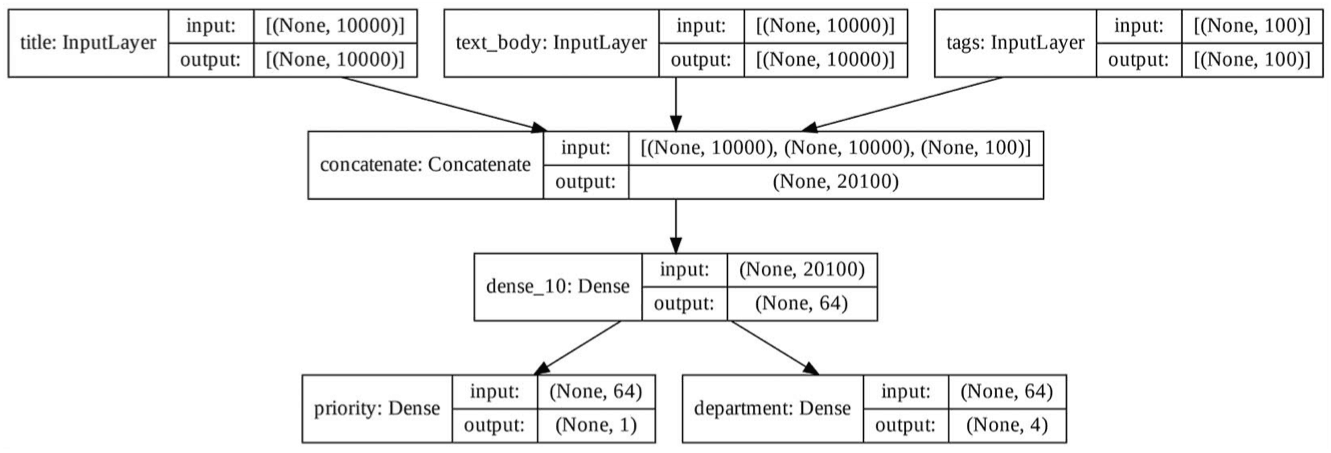
Now we can train the model by calling fit() with lists of input and output data. These lists of data should be in the same order as the inputs you passed to the Model constructor.
import numpy as np
num_samples = 1280
# Dummy input data
title_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
text_body_data = np.random.randint(0, 2, size=(num_samples, vocabulary_size))
tags_data = np.random.randint(0, 2, size=(num_samples, num_tags))
# Dummy target data
priority_data = np.random.random(size=(num_samples, 1)) department_data = np.random.randint(0, 2, size=(num_samples, num_departments))
model.compile(optimizer="rmsprop",
loss=["mean_squared_error", "categorical_crossentropy"],
metrics=[["mean_absolute_error"], ["accuracy"]])
model.fit([title_data, text_body_data, tags_data],
[priority_data, department_data], epochs=1)
model.evaluate([title_data, text_body_data, tags_data],
[priority_data, department_data])
priority_preds, department_preds = model.predict( [title_data, text_body_data, tags_data])


