Docling Application Tutorial
After trying different document parser projects, I am going to dive into IBM's open-source project Docling. I will introduce the most important modules and classes in this project.
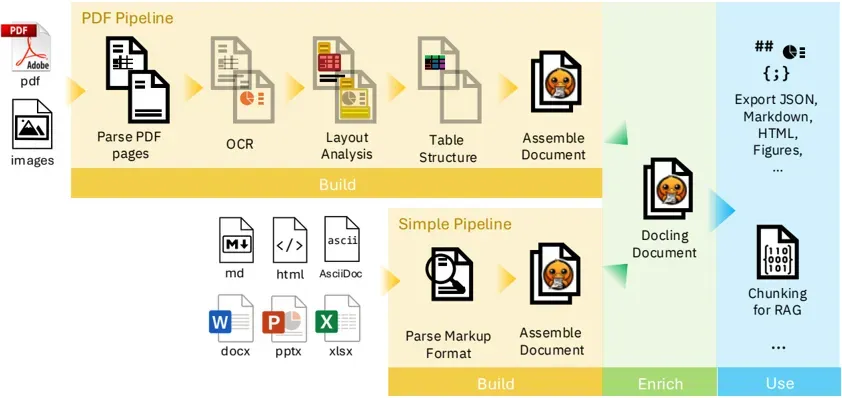
Important Docling Modules
The docling.document_converter module in the Docling project is the core module responsible for converting documents (like .docx, .pdf, .txt, etc.) into Docling’s structured format like .md or .json. Here are the list of Class in docling.document_converter module:
DocumentConverter– A high-level Python class designed for converting documents into a structuredDoclingDocumentformat.ConversionResult– Object returned byDocumentConverter.convert()method.FormatOption– Serves as the base class for all format-specific options passed toDocumentConverter. As an abstract base class,FormatOptioncannot be instantiated directly. Instead, it is subclassed for specific formats, such asPdfFormatOptionfor PDF documents orWordFormatOptionfor Word documents.InputFormat– Represents the supported input file formats thatDocumentConvertercan process. Each attribute of theInputFormatclass represents a distinct supported document type:PDF,DOCX,PPTX,HTML, .ectPdfFormatOption– A specialized subclass ofFormatOption, designed specifically to configure options for PDF document conversion within thedoclingframework. Thebackendattribute dictates the document backend responsible for handling PDF processing. Themodel_configattribute enables the use of arbitrary types within the model's configuration.ImageFormatOption– It is used to configure settings specific to image document conversion (e.g., PNG, JPEG, TIFF) within theDocumentConverterpipeline. This class enables customization of how image-based documents are processed, particularly for tasks like Optical Character Recognition (OCR) and other image-specific parsing requirements.WordFormatOption–It is designed to configure settings specific to Microsoft Word document conversion (e.g., .docx files) within theDocumentConverterpipeline. This class allows customization of how Word documents are processed, such as extracting text, tables, or other content during conversion.PowerpointFormatOptionMarkdownFormatOptionHTMLFormatOptionSimplePipeline– TheSimplePipelineclass is particularly useful for users who want a straightforward way to set up a document conversion workflow without manually configuring every aspect of theDocumentConverterand its associated options.StandardPdfPipeline–This is the default internal processing pipeline used by Docling to parse and convert PDF documents into structured Doc objects.
The docling.datamodel.pipeline_options module in the Docling library provides classes for configuring document conversion pipelines used by the DocumentConverter. Here are the list of Class in docling.datamodel.pipeline_options module:
BaseOptions– TheBaseOptionsclass in the serves as an abstract base class for pipeline configuration options used in document conversion processes. It provides a foundational structure for format-specific pipeline options classes, such asPdfPipelineOptions,AsrPipelineOptions, or others, ensuring a consistent interface for configuring document processing pipelines within theDocumentConverter.AsrPipelineOptions– Options for Automatic Speech Recognition (ASR) tasksEasyOcrOptions– Options for the EasyOCR engine.LayoutOptions– Options for layout processing.OcrEngine– Enum of valid OCR engines.OcrMacOptions– Options for the Mac OCR engine.OcrOptions– OCR options.PaginatedPipelineOptions– specifically for page-based processing pipelines (like those used for PDFs, DOCX, HTML, etc.). It includes settings important for page-level handling.PdfBackend– Enum of valid PDF backends.PdfPipelineOptions– Options for the PDF pipeline.PictureDescriptionApiOptions– designed for describing images via remote APIs—like self-hosted models (via VLLM or Ollama) or cloud AI services.PictureDescriptionBaseOptions–PictureDescriptionVlmOptions–PipelineOptions– Base pipeline options.ProcessingPipeline–RapidOcrOptions– Options for the RapidOCR engine.TableFormerMode– Modes for the TableFormer model.TableStructureOptions– Options for the table structure.TesseractCliOcrOptions– Options for the TesseractCli engine.TesseractOcrOptions– Options for the Tesseract engine.ThreadedPdfPipelineOptions– Pipeline options for the threaded PDF pipeline with batching and backpressure controlVlmPipelineOptions–
Simple Conversion
This is an simple example from Docling's documentation.
# Imports the DocumentConverter class from the docling library.
from docling.document_converter import DocumentConverter
# Defines the URL of the PDF document to be converted.
source = "https://arxiv.org/pdf/2408.09869"
# Create an instance of the DocumentConverter class.
converter = DocumentConverter()
# Call the convert method of the DocumentConverter object.
result = converter.convert(source)
# Call the export_to_markdown method of the document object to get the markdown representation of the document.
markdown = result.document.export_to_markdown()
print(markdown)The method DocumentConverter().convert() is the main entry point to convert documents (like .docx, .pdf, or .html) into a structured internal format that can then be exported (e.g., to Markdown, JSON, etc.). This method returns an object of type ConversionResult object. This ConversionResult object contains several useful properties, including:
.document(DoclingDocument) : The main parsed document as aDoclingDocumentobject, which you can export to Markdown, JSON, or other formats..status(ConversionStatus) : The conversion status (e.g., success, partial success, failure)..errors(List[ErrorItem]) : Any errors encountered during conversion..input(InputDocument) : Meta information about the input document.
The DoclingDocument class in the Docling Python library is a core data model representing a unified document structure. It is defined as a Pydantic model and serves as the central representation format for parsed and processed documents, regardless of the original input format (PDF, DOCX, HTML, images, etc.). DoclingDocument provides numerous methods for document manipulation and export:
export_to_markdown()export_to_html()export_to_document_tokens() (DocTags)export_to_dict()save_as_markdown– Save to markdown.
PDF to Markdown Conversion
There is another example that refers to custom conversion from docling's documentation.
# DocumentConverter is the main class that you use to perform the conversion. PdfFormatOption and InputFormat are used to specify the input format and its corresponding options.
from docling.document_converter import DocumentConverter, PdfFormatOption, InputFormat, StandardPdfPipeline
# PdfPipelineOptions is used to set general options for PDF processing, and TesseractCliOcrOptions is used to configure the Tesseract OCR engine.
from docling.datamodel.pipeline_options import PdfPipelineOptions, TesseractCliOcrOptions
# The PyPdfiumDocumentBackend backend is responsible for low-level PDF parsing and rendering pages into text and images for subsequent pipeline processing.
from docling.backend.pypdfium2_backend import PyPdfiumDocumentBackend
# Create and use DocumentConverter
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_cls=StandardPdfPipeline,
pipeline_options=PdfPipelineOptions(do_ocr=True, do_table_structure=True, enable_remote_services=False, images_scale=2, ocr_options=TesseractCliOcrOptions(lang=["chi_sim"]))
)
}
)In summary, the code above sets up a DocumentConverter that is configured to convert PDF files using the pypdfium2 backend. It will perform OCR using Tesseract with support for both Chinese and English, and it will try to preserve the structure of tables. Then we can convert PDF to markdown by:
# Defines the URL of the PDF document to be converted.
source = "https://arxiv.org/pdf/2408.09869"
# Call the convert method of the DocumentConverter object.
result = converter.convert(source)
# Call the export_to_markdown method of the document object to get the markdown representation of the document.
markdown = result.document.export_to_markdown()
print(markdown)DocumentCoverter is the key object. You can create a instance of DocumentCoverter by passing two parameters:
allowed_formatsrestricts input document types accepted by the converter.format_optionsallows detailed configuration of document processing pipelines and backend choices per input format.
DocumentConverter(
allowed_formats: Optional[List[InputFormat]] = None,
format_options: Optional[Dict[InputFormat, FormatOption]] = None
)
PDF to Markdown with Image Output
# DocumentConverter is the main class that you use to perform the conversion. PdfFormatOption and InputFormat are used to specify the input format and its corresponding options.
from docling.document_converter import DocumentConverter, PdfFormatOption, InputFormat, StandardPdfPipeline
# PdfPipelineOptions is used to set general options for PDF processing, and TesseractCliOcrOptions is used to configure the Tesseract OCR engine.
from docling.datamodel.pipeline_options import PdfPipelineOptions, TesseractCliOcrOptions
# The PyPdfiumDocumentBackend backend is responsible for low-level PDF parsing and rendering pages into text and images for subsequent pipeline processing.
from docling.backend.pypdfium2_backend import PyPdfiumDocumentBackend
# Create and use DocumentConverter
converter = DocumentConverter(
format_options={
InputFormat.PDF: PdfFormatOption(
pipeline_cls=StandardPdfPipeline,
pipeline_options=PdfPipelineOptions(do_ocr=True, do_table_structure=True, enable_remote_services=False, images_scale=2, generate_page_images=True, generate_picture_images=True, ocr_options=TesseractCliOcrOptions(lang=["chi_sim"]))
)
}
)ImageRefMode controls how images are referenced or embedded when exporting documents (e.g., to Markdown or HTML). Then we can convert PDF to markdown by:
# Defines the URL of the PDF document to be converted.
source = "https://arxiv.org/pdf/2408.09869"
# Call the convert method of the DocumentConverter object.
result = converter.convert(source)
# Call the save_as_markdown method of the document object to save the markdown representation of the document.
result.document.save_as_markdown("output.md", image_mode=ImageRefMode.REFERENCED)You can refer to DoclingDocument to know more about the save_as_markdown() method.
save_as_markdown(filename: Union[str, Path], artifacts_dir: Optional[Path] = None, delim: str = '\n\n', from_element: int = 0, to_element: int = maxsize, labels: Optional[set[DocItemLabel]] = None, strict_text: bool = False, escaping_underscores: bool = True, image_placeholder: str = '<!-- image -->', image_mode: ImageRefMode = PLACEHOLDER, indent: int = 4, text_width: int = -1, page_no: Optional[int] = None, included_content_layers: Optional[set[ContentLayer]] = None, page_break_placeholder: Optional[str] = None, include_annotations: bool = True)DOCX to Markdown Conversion with Image
from docling.document_converter import DocumentConverter, WordFormatOption, InputFormat, SimplePipeline
from docling.datamodel.pipeline_options import PaginatedPipelineOptions
from docling_core.types.doc import ImageRefMode
# Create and use DocumentConverter
converter = DocumentConverter(
format_options={
InputFormat.DOCX: WordFormatOption(
pipeline_cls=SimplePipeline,
pipeline_options=PaginatedPipelineOptions(generate_picture_images = True)
)
}
)
# Defines the URL of the PDF document to be converted.
source = r'https://calibre-ebook.com/downloads/demos/demo.docx'
# Call the convert method of the DocumentConverter object.
result = converter.convert(source)
# Call the save_as_markdown method of the document object to save the markdown representation of the document.
result.document.save_as_markdown("output.md", image_mode=ImageRefMode.REFERENCED)Multi-format conversion
You can configure the Docling converter to allow multiple input formats. Here, I’ll show an example that supports PDF and DOCX.
# Build a converter that can allow input of PDF and DOCX
from docling.document_converter import DocumentConverter, WordFormatOption, PdfFormatOption, InputFormat, SimplePipeline, StandardPdfPipeline
from docling.datamodel.pipeline_options import PaginatedPipelineOptions, PdfPipelineOptions, TesseractCliOcrOptions
from docling_core.types.doc import ImageRefMode
# Create and use DocumentConverter
converter = DocumentConverter(
allowed_formats=[InputFormat.DOCX, InputFormat.PDF],
format_options={
InputFormat.DOCX: WordFormatOption(
pipeline_cls=SimplePipeline,
pipeline_options=PaginatedPipelineOptions(generate_picture_images = True)
),
InputFormat.PDF: PdfFormatOption(
pipeline_cls=StandardPdfPipeline,
pipeline_options=PdfPipelineOptions(do_ocr=True, do_table_structure=True, images_scale=2, generate_page_images=True, generate_picture_images=True, ocr_options=TesseractCliOcrOptions(lang=["chi_sim", "es"]))
)
}
)Finally, I will present the complete code that converts PDF and DOCX files to Markdown, including image output and a user interface:
# Import necessary libraries for the UI and file handling.
import os
import gradio as gr
from pathlib import Path
# Import all the necessary modules from the docling library.
from docling.document_converter import DocumentConverter, WordFormatOption, PdfFormatOption, InputFormat, SimplePipeline, StandardPdfPipeline
from docling.datamodel.pipeline_options import PaginatedPipelineOptions, PdfPipelineOptions, TesseractCliOcrOptions
from docling_core.types.doc import ImageRefMode
# Initialize the DocumentConverter with the user-specified options.
# This object is created once and reused for each file conversion.
converter = DocumentConverter(
allowed_formats=[InputFormat.DOCX, InputFormat.PDF],
format_options={
InputFormat.DOCX: WordFormatOption(
pipeline_cls=SimplePipeline,
pipeline_options=PaginatedPipelineOptions(generate_picture_images=True)
),
InputFormat.PDF: PdfFormatOption(
pipeline_cls=StandardPdfPipeline,
pipeline_options=PdfPipelineOptions(
do_ocr=True,
do_table_structure=True,
images_scale=2,
generate_page_images=True,
generate_picture_images=True,
ocr_options=TesseractCliOcrOptions(lang=["chi_sim", "es"])
)
)
}
)
def convert_files_to_markdown(files):
"""
This function handles the file conversion logic.
Args:
files (list): A list of file objects uploaded via Gradio. Each object
has a `name` attribute which is the file path.
"""
if not files:
return "Please upload one or more files to convert."
# Get the user's desktop path.
# This uses a cross-platform method to find the user's home directory
# and then appends 'Desktop' to it. This should work on Windows, macOS, and Linux.
desktop_path = Path.home() / 'Desktop'
# Check if the desktop directory exists.
if not desktop_path.is_dir():
return f"Error: Could not find the desktop directory at {desktop_path}"
converted_files = []
# Loop through each uploaded file and convert it.
for file_obj in files:
try:
source_path = file_obj.name
# Use the original file name, but change the extension to .md
# and append "_converted" to avoid overwriting.
base_name = os.path.basename(source_path)
file_name, _ = os.path.splitext(base_name)
output_file_name = f"{file_name}_converted.md"
output_path = desktop_path / output_file_name
# Perform the conversion.
result = converter.convert(source_path)
# Save the markdown representation to the desktop.
result.document.save_as_markdown(str(output_path), image_mode=ImageRefMode.REFERENCED)
converted_files.append(str(output_path))
except Exception as e:
return f"An error occurred while converting {os.path.basename(file_obj.name)}: {e}"
# Return a success message with the paths of the new files.
return f"Successfully converted the following files to your desktop: {', '.join(converted_files)}"
# Create the Gradio interface.
# The `gr.File` component with `file_count="multiple"` allows for
# multiple files to be uploaded.
demo = gr.Interface(
fn=convert_files_to_markdown,
inputs=gr.File(file_count="multiple", label="Upload PDF or DOCX files"),
outputs=gr.Textbox(label="Status"),
title="Docling File Converter",
description="Upload multiple PDF or DOCX files to convert them to Markdown and save them to your desktop."
)
# Launch the Gradio app.
if __name__ == "__main__":
demo.launch()


